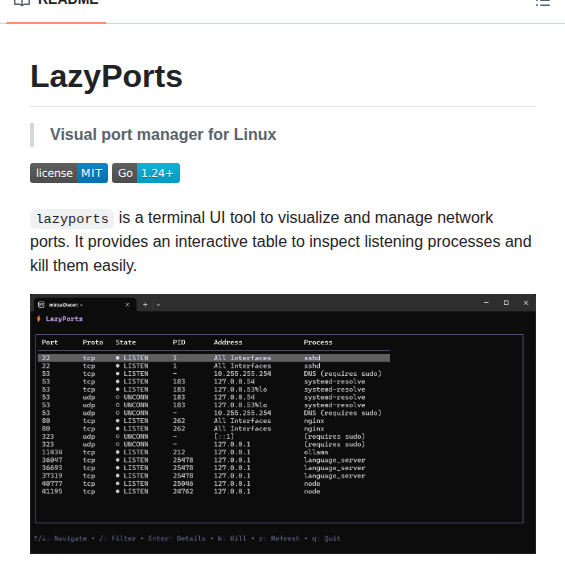
#парсинг
#парсинг
1) В основном я использую библиотеку Requests, где это возможно. Некоторые сайты имеют не задокументированные API, которые можно использовать.
2) Я пытаюсь использовать мобильные приложения и просматриваю запросы через Charles, потому что мобильная версия сайта может быть менее защищенной.
3) Я использую Selenium, когда другие методы не помогают или требуют скриншотов. Иногда я использую команду `xvfb-run -a python3 main.py` в связке с Selenium. Вот пример кода для установки виртуального фреймбуфера
```# устанавливаем пакет
apt-get install -y xvfb
# устанавливаем переменную дисплея
export DISPLAY=:0
# запускаем сервер Xvfb в фоновом режиме (один раз)
/usr/bin/Xvfb :0 -screen 0 1024x768x24 &
# подождите немного чтобы дать ему запуститься (один раз)
sleep 5
# добавьте префикс "xvfb-run" к "node" или "python" скрипту
xvfb-run -a node myscript.js
# или
xvfb-run -a python myscript.py
```4) Для решения капчи на русском языке я использую сервис RuCaptcha, а для английского языка - AntiCaptcha. В случае того, если нужно часто решать капчу, обучаю небольшую модель для распознавания текста.
5) Если я использую прокси в Selenium с Chrome, то я могу использовать его только после авторизации через IP. Вот пример кода, который я использую для добавления прокси:
```options.add_argument('--proxy-server=http://ip:port')
```6) Я использую BeautifulSoup только в тех случаях, когда мне предоставляется чистый HTML на сайте.
7) Не стесняйтесь найти готовый код на github!
8) Новичкам советую ознакомиться с этой статьей. Если бы она вышла лет 5 назад, это бы очень мне помогло для обучения :)
1) В основном я использую библиотеку Requests, где это возможно. Некоторые сайты имеют не задокументированные API, которые можно использовать.
2) Я пытаюсь использовать мобильные приложения и просматриваю запросы через Charles, потому что мобильная версия сайта может быть менее защищенной.
3) Я использую Selenium, когда другие методы не помогают или требуют скриншотов. Иногда я использую команду `xvfb-run -a python3 main.py` в связке с Selenium. Вот пример кода для установки виртуального фреймбуфера
```# устанавливаем пакет
apt-get install -y xvfb
# устанавливаем переменную дисплея
export DISPLAY=:0
# запускаем сервер Xvfb в фоновом режиме (один раз)
/usr/bin/Xvfb :0 -screen 0 1024x768x24 &
# подождите немного чтобы дать ему запуститься (один раз)
sleep 5
# добавьте префикс "xvfb-run" к "node" или "python" скрипту
xvfb-run -a node myscript.js
# или
xvfb-run -a python myscript.py
```4) Для решения капчи на русском языке я использую сервис RuCaptcha, а для английского языка - AntiCaptcha. В случае того, если нужно часто решать капчу, обучаю небольшую модель для распознавания текста.
5) Если я использую прокси в Selenium с Chrome, то я могу использовать его только после авторизации через IP. Вот пример кода, который я использую для добавления прокси:
```options.add_argument('--proxy-server=http://ip:port')
```6) Я использую BeautifulSoup только в тех случаях, когда мне предоставляется чистый HTML на сайте.
7) Не стесняйтесь найти готовый код на github!
8) Новичкам советую ознакомиться с этой статьей. Если бы она вышла лет 5 назад, это бы очень мне помогло для обучения :)